Datasets
 USPTex
USPTex
This is a texture dataset with 2292 images from 191 texture classes. The USPtex was made regarding textures typically found daily, such as seeds, rice, tissues, road scenes, various types of vegetation, walls, clouds, soils, blacktop, and gravel. Each database entry class is a set of 12 sub-texture samples extracted from examples (images of 512x384) of a particular material without overlapping. So, the database is composed by 2292 samples of 191 texture classes (12 samples per class).
Examples

ShapeCN - Dataset of the paper "A complex network-based approach for boundary shape analysis"
The ShapeCN is the dataset of the paper Backes, A.R., Casanova D. and Bruno, O.M. "A complex network-based approach for boundary shape analysis", Pattern Recogntion, 42(1):54-67, 2009
It is a countour dataset of leaves and fishes. The leaves dataset is composed by leaves from different plants. Leaves classification is a difficult task, as the between-class similarity is considerable while the within-class similarity is not suitable. Besides, overlaps can occur between adjacent parts of leaves. As a result, there can be major differences among boundary contours of leaves in the same category. The fishes dataset objectives to show the performance of the method on large databases composed by shapes under rotation and scale transformations.
Examples


1200Tex - Dataset of the paper "Plant leaf identification using Gabor wavelets"
The 1200Tex is the dataset of the paper Casanova, D., Sa, J.J.M. and Bruno, O.M. "Plant leaf identification using Gabor wavelets", International Journal of Imaging Systems and Technology, 19(3):236--243, 2009
It is a texture leaf dataset. Samples were collected in vivo and each leaf was washed to remove impurities. Afterward they were adjusted so that their central axis (line that connects the basal and apical ends)stayed in a vertical position and were digitalized individually with adesktop scanner. A resolution of 1200 dpi (dots per inch)was used to obtain leaf texture images with more details. A total of 400 samples, divided into 20 classes (20 samples perclass), were collected. This is a microtexture dataset, this way, three windows (128 x 128 pixels) were extracted manually from each sample making a total of 1200 textures (400 samples x 3 windows).
Examples


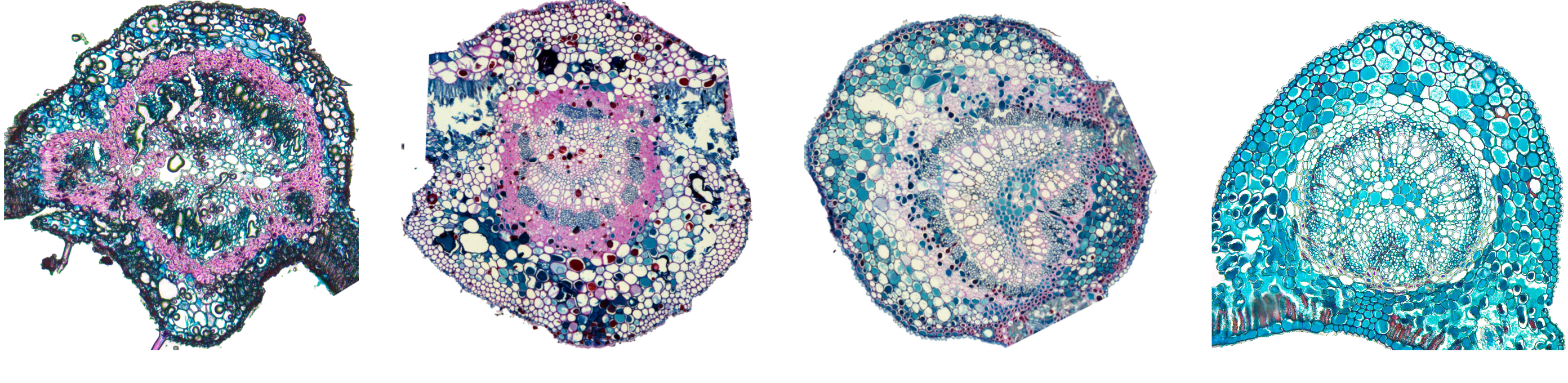
Midrib - Dataset of the paper "Plant identification based on leaf midrib cross-section images using fractal descriptors"
Midrib is the dataset of the paper Silva, N. R.; Florindo, J. B.; Gómez, M. C.; Rossatto, D. R.; Kolb, R. M.; Bruno, O. M. "Plant identification based on leaf midrib cross-section images using fractal descriptors", Plos One (in press), 2015
The Midrib is a dataset of midrib leaves. Samples of leaves were collected from 50 species in the Cerrado biome in central Brazil, at IBGE (Brazilian Institute of Geography and Statistics) Ecological Reserve. At least four leaves (one per individual) were sampled for each species. All samples were obtained from fully expanded leaves collected from the third and fourth nodes from the branch tip. Middle regions of the leaf, including the midrib, were fixed in FAA 70 (Formalin, Acetic acid, 70% Alcohol) for 48 hours. These were dehydrated in an ethanol series and embedded in paraffin. The thickness of the cross sections was 8µm. The sections were stained with astra blue 1% and basic fuchsin 1%, both from Sigma, and mounted with Entellan®. The images of midribs were captured in 10x objective lens, using a trinocular microscope Axio Lab A1 coupled to a digital camera Axiocam ICc 1.
Examples